Reproducible Analytical Pipelines For All
173,546,968,245,459,461,603,328
bytes of data/information created, captured copied, and consumed worldwide by the end of 2024.
97 trillion Blu-ray discs
Source: IDC Global DataSphere Forecast 2021-2025
On two occasions I have been asked, "Pray, Mr. Babbage, if you put into the machine wrong figures, will the right answers come out?"... I am not able rightly to apprehend the kind of confusion of ideas that could provoke such a question.











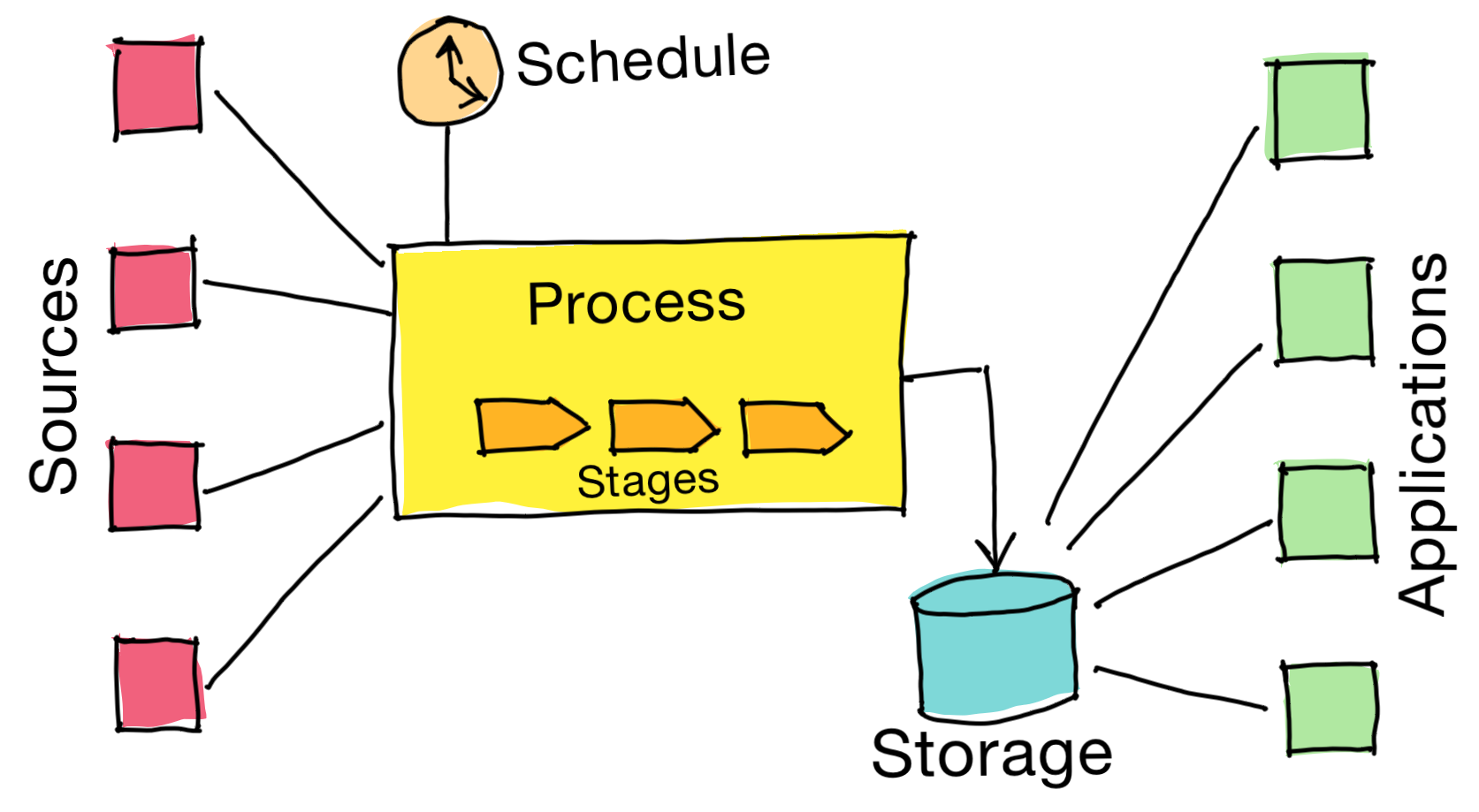
Building blocks
Stage Scripts
Keep stages small
Extract, transform, load
Tech stack not that important!
e.g. Python + PETL
import petl
conn = db.connect(...)
petl.fromdb(
conn, 'SELECT * FROM example'
).convert(
'value', float
).unpack(
'complex_column', ['p', 'q']
).tocsv(
'example.csv'
)
Building blocks
Orchestration
DVC → graph
stages:
extract:
cmd: python extract.py
outs:
- extract.csv
transform:
cmd: python transform.py
deps:
- extract.csv

Building blocks
Data storage
| Location | SCM | GitHub, GitLab, BitBuckect, etc |
| Cloud storage | AWS S3, Azure Blob | |
| Format | CSV | Very widely usable |
| Parquet | Efficient for big data |
Building blocks
Scheduling
Every night? External trigger?
CI pipelines have many triggering options
e.g. GitHub Actions
name: pipeline
"on":
workflow_dispatch:
schedule:
- cron: "15,45 6-8 * * 1-5"
jobs:
run-pipeline:
runs-on: ubuntu-latest
steps:
- name: Run DVC pipelines
run: |
pipenv run dvc repro -R pipelines
Thank you!

Get these slides